
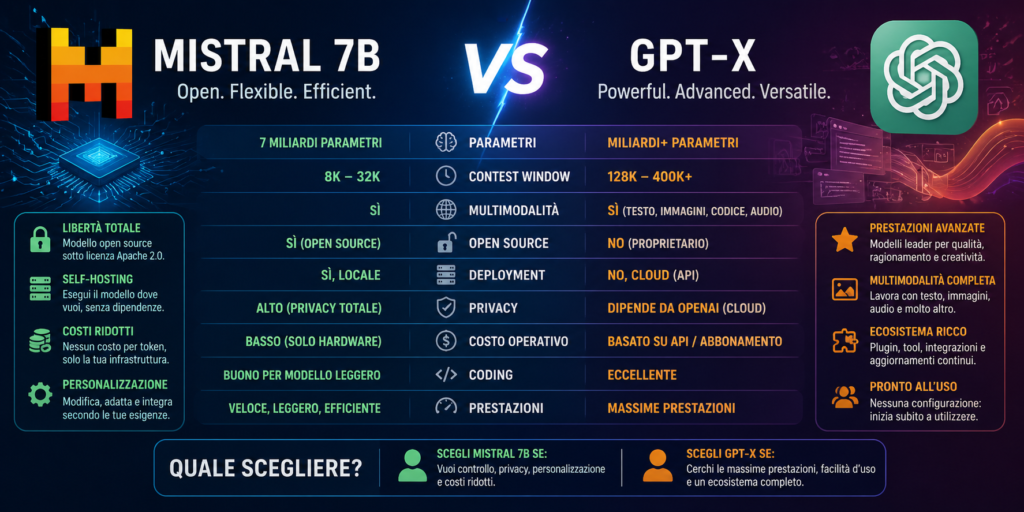
Meno di quanto si possa credere. Con un buon hardware puoi settare modelli in locale già molto competitivi per la maggior parte dei compiti, a costo zero. Il gap reale non è nella qualità delle risposte: è negli strumenti che ci stanno intorno.
La sensazione di pagare qualcosa che puoi avere gratis
La prima volta che hai usato Qwen su Leo di Brave, o che ti hanno risposto dei modelli sconosciuti su Arena, probabilmente ti aspettavi qualcosa di chiaramente inferiore. Risposte più corte, ragionamento più piatto, errori evidenti. Invece no. La risposta era buona. A volte molto buona. E completamente gratuita.
Chi ha provato questi modelli sa già di cosa si parla. Non sono esperimenti: sono strumenti utilizzabili, spesso su compiti che fino a poco fa avresti affidato solo a ChatGPT o Claude. La sensazione che rimane è strana: sto davvero pagando un abbonamento per qualcosa che esiste già gratis?
La risposta onesta è: dipende da cosa fai. Ma per una parte significativa dei compiti quotidiani, la risposta è sì.

Cosa misurano davvero i benchmark (e cosa ignorano)
Quando esce una nuova versione di un modello frontier, arrivano sempre i grafici: MMLU, HumanEval, MATH, GPQA. Numeri alti, confronti schiaccianti, gap evidenti. E sono numeri reali, non inventati.
Il problema è cosa misurano. Questi benchmark testano i casi limite: ragionamento matematico avanzato, coding su problemi complessi, domande accademiche di alto livello. Sono utili per capire il soffitto di un modello. Non misurano quanto bene riesce a riscrivere una email, riassumere un documento, strutturare un piano, rispondere a una domanda diretta.
Nella maggior parte dei contesti quotidiani, quei parametri non entrano in gioco. Spesso misurano capacità che nella pratica reale non si manifestano in quel modo, e che difficilmente faranno la differenza nel tuo lavoro di tutti i giorni. Un modello che segna 45% su un benchmark di ragionamento matematico avanzato può rispondere benissimo al 90% delle domande che fai ogni giorno. I benchmark misurano le vette, non il territorio dove lavori.
MoE: come un modello da 32B può competere con 50 trilioni di parametri
Si vocifera che GPT-5 abbia oltre 50 bilioni di parametri. Un numero che intimidirebbe chiunque, soprattutto confrontato con un modello locale da 32 miliardi. Il confronto sembra impari. In realtà non lo è, e il motivo si chiama MoE — Mixture of Experts.
L’idea di base è questa: invece di avere tutti i parametri attivi su ogni singola richiesta, il modello è diviso in sotto-reti specializzate chiamate “esperti”. Per ogni input, solo una parte di questi esperti viene attivata, quella più rilevante per quel tipo di compito. Il risultato è un modello che sulla carta ha molti parametri totali, ma che per ogni singola risposta ne usa una frazione.
Puoi approfondire questo affascinante argomento con questo articolo:
MoE: cos’è e perché è una delle scoperte del secolo.
Questo significa due cose concrete. Prima: un modello MoE da 32B attivi può raggiungere la qualità di un modello denso molto più grande, perché ogni esperto è specializzato. Seconda: gira su hardware accessibile, perché i parametri attivi in un dato momento sono una parte del totale.
In locale, modelli come Qwen3 32B MoE o DeepSeek-V3 producono risultati che, su task medi e avanzati, non hanno niente da invidiare ai modelli frontier su quegli stessi task.
E se i modelli di frontiera utilizzano anch’essi struttura MoE, quanti miliardi di parametri bastano davvero per i compiti di cui hai bisogno? Anzi, in alcuni casi più parametri possono significare meno efficienza su task specifici. Se sei curioso di capire cosa intendo, puoi leggere ChatGPT è peggiorato? La regressione che nessuno vuole ammettere.
Dove i modelli gratuiti reggono e dove no
Su scrittura, riassunti, brainstorming, risposta a domande dirette, analisi di testi, traduzione, strutturazione di idee: i modelli gratuiti e locali reggono bene. In molti casi la differenza con un frontier è impercettibile nell’uso reale.
Il gap diventa reale su tre fronti specifici. Il primo è il ragionamento complesso a catena: problemi che richiedono molti passaggi logici consecutivi senza perdere il filo. Il secondo è il contesto molto lungo: documenti enormi, conversazioni estese, progetti con molta storia alle spalle. Il terzo è il coding avanzato: non scrivere una funzione, ma ragionare su architetture complesse e debug su sistemi intricati.
Su tutto il resto, la domanda giusta non è “quale modello è migliore” ma “quale modello è sufficiente per questo compito“. E la risposta, più spesso di quanto si pensi, è un modello gratuito.
La distinzione vera non è gratuito vs a pagamento: è tra chi rende il modello accessibile a tutti e chi lo tiene sotto chiave. Modelli proprietari vs open weight: cosa cambia davvero
Hai davvero bisogno di un modello frontier?
La risposta dipende quasi sempre dall’ecosistema, non dalla potenza bruta.
Claude vince non perché abbia risposte miracolosamente superiori su ogni compito. Vince perché ha i Progetti con system prompt e file di contesto, il RAG cross-chat, Claude in Chrome: una struttura che permette di lavorare in modo continuativo senza perdere il filo. GPT vince su certi fronti per la DeepSearch e per l’integrazione con altri strumenti. Sono vantaggi reali, ma sono vantaggi di ecosistema, non di risposta.
Un modello locale con MoE, usato con un buon sistema di prompt e contesto, copre la grande maggioranza dei compiti quotidiani a costo zero. I casi in cui hai davvero bisogno di tutto quello che offrono 50 trilioni di parametri sono meno di quanto il marketing suggerisca.
La domanda vera non è se i modelli gratuiti siano inferiori. È se la differenza vale il prezzo che stai pagando, per quello che fai tu, ogni giorno.
Se vuoi conoscere un altro modo per usare AI potenti ma in cloud in modo completamente gratuito puoi leggere OpenRouter: come usare modelli AI potenti completamente gratis.