
La Mixture of Experts è l’architettura AI che permette a un modello da trilioni di parametri di rispondere con il costo computazionale di uno molto più piccolo. È rimasta ferma per vent’anni. Poi è diventata il cuore di GPT-4, Gemini e DeepSeek.

Il problema: i modelli AI costano troppo per quello che fanno
Ogni volta che scrivi un messaggio a ChatGPT o a Gemini, il modello attiva centinaia di miliardi di parametri. Anche se stai chiedendo come si chiama la capitale della Francia.
Questa è la logica dei modelli densi: tutti i parametri partecipano a ogni risposta, indipendentemente dalla complessità della domanda. Più il modello cresce, più il costo di ogni singola inferenza [tooltip: inferenza] cresce con lui.
Il risultato è un problema strutturale: per migliorare le prestazioni bisogna aumentare le dimensioni del modello, ma aumentare le dimensioni significa aumentare i costi di calcolo, il consumo energetico e il tempo di risposta. Ad un certo punto la matematica smette di funzionare.
La Mixture of Experts rompe questo schema. Non eliminando i parametri, ma selezionando quali attivare di volta in volta.
Cos’è l’architettura MoE: un team di esperti per ogni domanda
Immagina uno studio medico con dieci specialisti: un cardiologo, un neurologo, un ortopedico, un dermatologo e così via. Quando arrivi alla reception, l’addetto non ti manda da tutti e dieci. Ti manda dallo specialista più adatto al tuo problema. Gli altri restano disponibili, ma non si muovono.
Un modello MoE funziona nello stesso modo. È composto da tanti sottomodelli specializzati — gli esperti — e da un componente centrale chiamato gating network [tooltip: gating network]. Per ogni token [tooltip: token] in arrivo, il gating network decide quali esperti attivare, solitamente due o quattro su decine o centinaia disponibili.
Il resto del modello resta fermo. Non consuma risorse, non rallenta la risposta.
Il risultato è che un modello MoE da 400 miliardi di parametri può avere il costo computazionale di uno denso da 50 miliardi. La capacità è quella del modello grande. Il costo è quello del modello piccolo.
Modelli delle migliori aziende AI, tutti gratuiti
Il punto più interessante di Leo non è solo che è gratis. È che dentro trovi i modelli delle principali aziende AI attualmente sul mercato, ognuna rappresentata da almeno un modello.
Nella versione gratuita sono disponibili, tra gli altri: Claude Haiku di Anthropic, Llama 4 Scout e Llama 4 Maverick di Meta, Qwen VL 30B di Alibaba, GPT OSS 20B di OpenAI. La lista cambia nel tempo man mano che Brave aggiorna i modelli disponibili, ma il principio rimane lo stesso: non sei legato a un’unica azienda o a un unico approccio.
Puoi passare da un modello all’altro in pochi secondi dal menu a tendina, senza uscire dalla conversazione. Se vuoi capire quale AI si adatta meglio alle tue esigenze di scrittura, puoi leggere anche la guida alle Migliori AI per scrivere nel 2026.
Il piano Premium a circa 15 euro al mese sblocca modelli più potenti e limiti più alti, ma per la maggior parte degli utenti il piano gratuito è già più che sufficiente per l’uso quotidiano durante la navigazione.
La storia: quattro ricercatori, un paper del 1991 e vent’anni di silenzio
Tutto inizia con un paper di nove pagine pubblicato nel marzo 1991 sulla rivista Neural Computation. Il titolo è “Adaptive Mixtures of Local Experts”. Gli autori sono quattro ricercatori del MIT e dell’Università di Toronto: Robert Jacobs, Michael Jordan, Steven Nowlan e Geoffrey Hinton.
L’idea è già completamente formulata: un sistema composto da reti neurali separate, ognuna specializzata su un sottoinsieme del problema, coordinate da un meccanismo di smistamento. La struttura di base di ogni modello MoE moderno è già lì, nel 1991.
Il paper viene letto, citato, poi messo da parte. Per quindici anni non succede niente di rilevante.
Geoffrey Hinton nel 2024 vince il Premio Nobel per la Fisica — sì, per la Fisica — per il suo lavoro fondativo sulle reti neurali artificiali. Lo condivide con John Hopfield. Quando la Royal Swedish Academy of Sciences lo chiama al telefono nella sua stanza d’albergo in California, la sua prima reazione è: “aspetta, io non faccio fisica. Potrebbe essere uno scherzo.” Non era uno scherzo. Hinton ha lasciato Google nel 2023 per parlare liberamente dei rischi dell’AI.
Il paper del 1991 accumula citazioni lentamente. Poi, nel 2017, Noam Shazeer di Google pubblica “Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer”. Il riferimento a Jacobs, Jordan, Nowlan e Hinton è esplicito. L’idea originale viene adattata ai transformer moderni e ai dataset di scala industriale.
Da quel momento la corsa inizia. Nel 2021 Google pubblica il Switch Transformer, che scala MoE fino a 1,6 trilioni di parametri. Nel 2023 arriva Mixtral di Mistral AI, il primo modello MoE open weight [tooltip: open weight] di alta qualità accessibile a chiunque. Nel 2024 e 2025 i documenti ufficiali di Gemini 2.5 e DeepSeek-V3 confermano MoE come architettura di base.
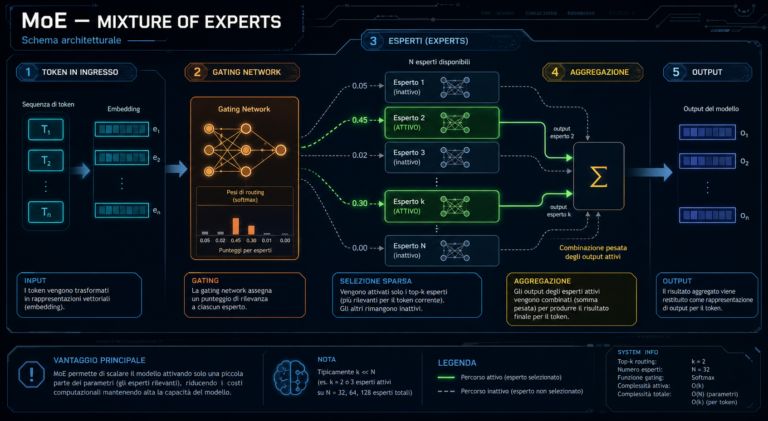
Cosa fa MoE in numeri concreti
L’esempio più citato è Mixtral 8x7B: 46 miliardi di parametri totali, distribuiti tra otto esperti da 7 miliardi ciascuno. Per ogni token, il gating network ne attiva due. Il costo computazionale effettivo è quello di un modello da circa 12 miliardi di parametri, non da 46.
Su scala industriale le proporzioni diventano più estreme. DeepSeek-V3 ha 685 miliardi di parametri totali ma attiva una frazione ben inferiore per ogni token. GPT-4 non ha confermato ufficialmente la propria architettura, ma fonti tecniche molto citate indicano una struttura MoE con più esperti distribuiti su hardware separato. Claude di Anthropic non ha mai comunicato dettagli architetturali ufficiali, ma la combinazione di prestazioni, velocità di risposta e struttura dei costi rende MoE l’ipotesi quasi certa: con quei prezzi e quella infrastruttura, un modello denso non reggerebbe.
I vantaggi si misurano su tre dimensioni:
- Costo di inferenza: attivare il 10-20% dei parametri anziché il 100% riduce direttamente il consumo energetico e il costo per risposta.
- Velocità: meno calcoli per token significa latenza più bassa, risposte più rapide.
- Capacità totale: il modello può “sapere di più” perché ha più parametri totali, pur pagando solo per quelli usati.
Il documento tecnico di Gemini 3 Pro lo sintetizza in modo diretto: MoE permette di “La suddivisione tra capacità totale del modello e costo computazionale per ogni singolo token.”. Capacità e costo vengono separati. Questo era impossibile con i modelli densi.
Perché MoE non è un’ottimizzazione ma un cambio di paradigma
I modelli densi hanno un soffitto. Oltre una certa dimensione, il costo per migliorare le prestazioni cresce più velocemente delle prestazioni stesse. MoE sposta questo soffitto molto in alto.
Non è un’alternativa all’architettura transformer: è un’estensione di essa. I modelli MoE moderni sono transformer in cui i layer feed-forward vengono sostituiti da un insieme di esperti con routing dinamico. Il transformer resta, ma il modo in cui usa i propri parametri cambia completamente.
La traiettoria è già visibile: Gemini, DeepSeek, Mixtral, molto probabilmente GPT-4 e quasi certamente Claude sono tutti MoE. Chi vuole capire come funzionano davvero i sistemi AI che usa ogni giorno deve passare da qui.
Un MoE ha risolto un problema enorme: separare capacità e costo. Ma il problema successivo è già sul tavolo. Esiste già un’architettura chiamata Mamba che promette di fare per la memoria quello che MoE ha fatto per il calcolo: elaborare sequenze lunghissime in tempo lineare invece che quadratico, con costi di inferenza drasticamente più bassi. I ricercatori hanno già combinato le due cose in un unico sistema — MoE-Mamba — che raggiunge le stesse prestazioni di Mamba in 2,2 volte meno passi di training. La domanda non è se arriverà qualcosa dopo MoE. È già arrivato. La domanda è se, come nel 1991, ci vorrà vent’anni perché qualcuno capisca cosa ha in mano.
Il paper aveva ragione. Ci ha messo solo vent’anni a dimostrarlo.